Postgres에 있는 문자를 자연어 검색을 할 필요가 있어서 자연어 검색에 대해서 찾은 내용들을 정리해 볼까 한다. 먼저 테스트 환경은 다음과 같다.
M1 Pro, postgres 14.x, organization 테이블의 name 칼럼에 100만개의 문자열 입력
동일한 문자열을 구하는 방법은 다음과 같다.
select name from organization where name = '문자열'
하지만 해당 sql은 완벽히 매치가 되는 문자열에 대해서만 검색이 가능하므로, index를 추가하면 검색 속도는 좋아지겠으나 exact match만 지원하므로 검색에 제한이 생긴다.
다음 방법은 like를 사용한 full text search를 사용하는 방법이다. 사용법은 다음과 같다.
select name from organization where name like '%문자열%'
해당 방법은 name 중간에 '문자열' 이라는 문구가 있으면 모두 출력한다. 하지만 일반적인 index를 추가하게 되면 문맥에 상관없이 순서대로 인덱싱이 되므로, seq scan을 하게 된다. 이것을 해결하기 위해서 현대의 DB에는 full text search를 지원하는 인덱스가 있다. postgres에서도 full text search를 지원하는 인덱스가 있다. gin index를 사용하면 된다. 사용법은 다음과 같다.
-- 확장 프로그램 설치
CREATE EXTENSION pg_trgm;
-- name_origin_gin_idx 인덱스를 추가한다. name 칼럼을 gin_trgm_ops를 사용한 gin 인덱스를 사용한다.
CREATE INDEX name_origin_gin_idx ON organization USING gin(name gin_trgm_ops);
이제 gin index가 없을 때와 있을 때의 cost를 확인해 보자.


좌측이 gin index 없을때, 우측이 gin index가 있을 때다. 좌측을 보면 cost가 많이 들어 병렬 쿼리를 사용함에도 불구하고, 우측 cost에 비해서 비용이 많이 드는 것을 볼 수 있다. (gin index 없을 때 25500, gin index 있을 떄 440, 숫자가 적을수록 대체로 비용이 적고 빨리 검색이 된다) 그래서 정규표현식 쿼리도 사용이 가능하긴 하나, 사용 경우에 따라서 index를 사용하지 못할 확률이 매우 높다.
그래서 여기서 조금 더 찾아보니 tsvector와 tsquery가 있었다. 해당 기능들을 사용해서 검색 쿼리에 대한 매칭 ranking, 오타 허용 오차 등에 대해서 다룰 수 있는 것 같았다.
tsvector는 string을 어휘소 기반으로 바꾼 결과 자료형이고, to_tsvector는 문자열을 tsvector 형태로 바꾸는 함수이다. 사용법은 다음과 같다.
select * from to_tsvector('Gleason, Gottlieb and Dicki 88');
-- 결과물
to_tsvector
'88':5 'dicki':4 'gleason':1 'gottlieb':2and나 ',' 같은 의미가 거의 없는 단어를 제외하고는 단어와 단어의 위치가 역인덱스되어 보이는 것을 알수 있다. 그래서 이것을 활용해서 인덱스 칼럼을 새로 생성해서 검색을 진행할 수 있다. 인덱스 칼럼을 새로 만들어 검색을 해 보자.
-- 칼럼 추가
alter table organization add column tsvec_words tsvector;
-- 칼럼에 내용 추가
UPDATE organization SET tsvec_words = to_tsvector(name);
-- 칼럼에 인덱스 추가 (실제 애플리케이션에 사용하려면 name 업데이트 시 tsvec_words도 같이 업데이트하는 전략 필요)
CREATE INDEX name_gin_idx ON organization USING gin(tsvec_words);
이제 tsvec_words는 인덱스 칼럼이다. 해당 인덱스를 사용해서 검색을 해 보자.
select * from organization where tsvec_words @@ to_tsquery('King & (Group | Erdman)');
-- 추가 쿼리
-- King과 10이 근접한 경우
select * from organization where tsvec_words @@ to_tsquery('King <-> 10');
-- King과 10 사이에 1개의 단어(2개의 공백)가 있는 경우
select * from organization where tsvec_words @@ to_tsquery('King <2> 10');첫번째 쿼리를 확인해 보았다. King이라는 단어가 포함되고 Group 또는 Erdman이 포함되어야 한다. 해당 쿼리의 결과는 다음과 같이 잘 나온다.
King Group 58,'58':3 'group':2 'king':1
King Group 69,'69':3 'group':2 'king':1
King Group 41,'41':3 'group':2 'king':1
King Group 74,'74':3 'group':2 'king':1
King Group 78,'78':3 'group':2 'king':1
King - Erdman 17,'17':3 'erdman':2 'king':1
...해당 쿼리의 cost를 확인해 보면 다음과 같다.
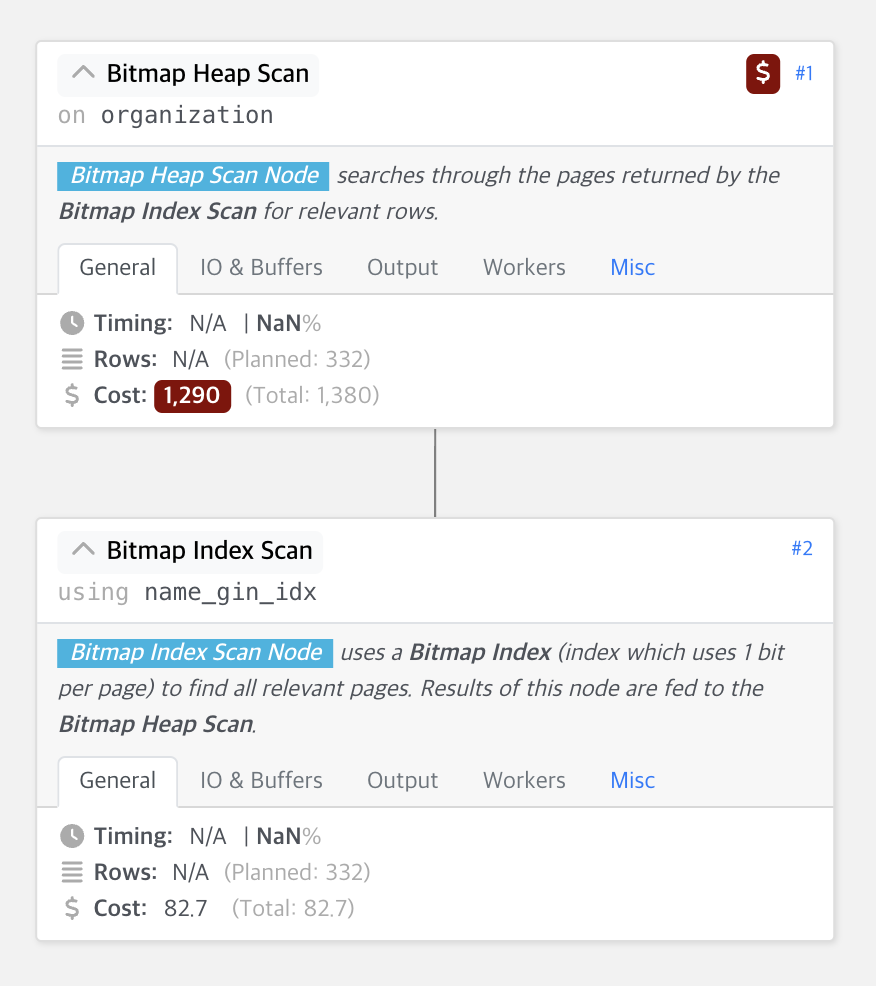
단순한 like 검색도 아니고 or, and 조건 + 문자열 중간에 포함 이라는 비교적 복잡한 조건이 들어갔음에도 불구하고, 1400대의 cost가 나왔다. 이정도면 괜찮아 보이는 검색 성능이다. 이 방법은 앞에서 말했듯이 name 칼럼이 바뀔때마다 tsvec_words 칼럼이 자동으로 업데이트되어야 하는 전략이 필요하다. ORM에서 설정하거나 DB function에서 설정하면 될 것 같다.
많은 방법들을 찾았지만, 실제 검색 엔진에서 결과를 보여줄 때는 일치도를 포함해서 결과를 출력할 수도 있다. ts_rank는 단어의 빈도를 확인하고, ts_rank_cd는 일치하는 어휘의 근접성을 고려한다고 한다. rank를 포함한 결과를 확인해보자.
SELECT *, ts_rank(tsvec_words, query) AS rank
FROM organization, to_tsquery('King|Group') query
WHERE query @@ tsvec_words
ORDER BY rank DESC;
해당 쿼리를 사용해서 일치도가 존재하는 쿼리 결과를 볼 수 있다. 해당 쿼리의 cost도 확인해보자.

Rank를 사용하는 쿼리는 상당히 cost가 많이 드는 것을 확인할 수 있다. 해당 원인은 postgres의 공식 문서에서 확인할 수 있었다.
Ranking can be expensive since it requires consulting the tsvector of each matching document, which can be I/O bound and therefore slow. Unfortunately, it is almost impossible to avoid since practical queries often result in large numbers of matches.
즉, 각 ROW에 대항하는 모든 tsvector를 참고해야해서 비용이 많이 든다는 말이다. 그래서 검색 관련한 쿼리의 요청이 많을 경우에는 해당 쿼리를 사용하는 것에 대해서 생각할 필요가 있어 보인다.
참고자료
https://xata.io/blog/postgres-full-text-search-engine
Create an advanced search engine with PostgreSQL
PostgreSQL provides the necessary building blocks for you to combine and create your own search engine for full-text search. Let's see how far we can take it.
xata.io
PostgreSQL에서 NLP 자연어 기반 구문 검색하기(Full Text 검색 기능)
오늘은 PostgreSQL을 MongoDB처럼 패턴 검색과 색인 기능을 사용하는 방법을 안내하고자 합니다. P...
blog.naver.com
https://junhkang.tistory.com/2
Full Text Search를 활용한 데이터베이스 성능 향상
1. 문제상황 긴 텍스트에서 단순 like 조합 외 방법으로 유사 문자열 검색 (Ex. Susan loves hiking 을 “love hike” 이라는 키워드로 검색하고자 함) RDBMS에서 수천만 건의 데이터 처리 시 긴 문자열 검색
junhkang.tistory.com
https://www.postgresql.org/docs/current/textsearch-controls.html
12.3. Controlling Text Search
12.3. Controlling Text Search # 12.3.1. Parsing Documents 12.3.2. Parsing Queries 12.3.3. Ranking Search Results 12.3.4. Highlighting Results To implement full …
www.postgresql.org
'서버 인프라 > DB' 카테고리의 다른 글
| Slow query 개선 경험기 (0) | 2024.10.30 |
|---|---|
| template database "template1" does not exist 에러 해결하기 (0) | 2022.11.21 |
| RDS Postgresql 로컬에서 실행하기 (0) | 2022.09.27 |
| [Prisma] Can't reach database server at `db` 에러 해결하기 (IN 연산 관련) (0) | 2022.02.26 |
| Postgresql DB의 인덱싱 알고리즘 (0) | 2021.12.26 |